
Google의 AI연구팀인 Google AI가 저해상도 이미지에 노이즈를 추가하여 '순수한 노이즈'가 될 때까지 가공해 고해상도 이미지를 생성하는 'diffusion model(확산모델)'이라는 기법을 개선하는 새로운 접근방식을 발표했습니다. '화질이 나쁜 저해상도 이미지에서 고해상도 이미지를 생성하는 기술'은 오래된 사진의 복원, 의료영상의 개선 등 폭넓은 용도가 상정되어 있어 기계학습의 활약이 기대되는 작업 중 하나입니다.
Google AI Blog: High Fidelity Image Generation Using Diffusion Models
https://ai.googleblog.com/2021/07/high-fidelity-image-generation-using.html
High Fidelity Image Generation Using Diffusion Models
Posted by Jonathan Ho, Research Scientist and Chitwan Saharia, Software Engineer, Google Research, Brain Team Natural image synthesis is a...
ai.googleblog.com
Enhance! Google researchers detail new method for upscaling low-resolution images with impressive results: Digital Photography Review
https://www.dpreview.com/news/0501469519/google-researchers-detail-new-method-upscaling-low-resolution-images-with-impressive-results
Enhance! Google researchers detail new method for upscaling low-resolution images with impressive results
Google might just be turning CSI's laughable 'Enhance!' scenes into a reality.
www.dpreview.com
Google's New AI Photo Upscaling Tech is Jaw-Dropping | PetaPixel
https://petapixel.com/2021/08/30/googles-new-ai-photo-upscaling-tech-is-jaw-dropping/
Google's New AI Photo Upscaling Tech is Jaw-Dropping
Google shares its latest breakthroughs in the area of using artificial intelligence to upscale low-res photos, and the results are amazing.
petapixel.com
일반적으로 낮은 해상도의 이미지에서 고해상도 이미지를 복원하는 작업에는 적대적생성네트워크(GANs), 변분적오토인코더(VAE), 자기회귀모델 등의 생성모델이 사용되고 있습니다. 그러나 GANs는 생성하는 이미지 대부분이 복제되어 버리는 모드붕괴(mode collapse)가 발생할 수 있고 자기회귀모델은 합성속도가 느리다는 문제점이 있는 등 생성모델에는 결점이 있다는 것.
한편 Google AI가 2015년에 발표한 '확산모델'이라는 생성모델은 트레이닝의 안정성과 생성이미지 및 음성의 품질이 높아 최근 재평가가 이루어지고 있다고 합니다. 그리고 새롭게 Google AI는 'Super-Resolution via Repeated Refinements(SR3)', 'Cascaded Diffusion Models(CDM)'라는 2가지의 새로운 확산모델 접근법을 사용함으로써, 확산모델의 이미지합성 품질을 향상시키는데 성공했다고 합니다.

SR3는 먼저 저해상도 이미지에 가우스잡음을 서서히 추가해 '순수한 노이즈 이미지'가 될 때까지 손상시킨다는 것. 그 후 트레이닝시킨 신경망으로 이미지의 손상과정을 반전시킴으로써 노이즈를 제거해 당초의 해상도를 넘는 고해상도 이미지를 생성하는 원리입니다.
왼쪽이 입력데이터인 64×64픽셀의 저해상도 이미지이며, 오른쪽은 저해상도 이미지에 가우스잡음을 추가하여 '순수한 노이즈 이미지'로 만든 것입니다.
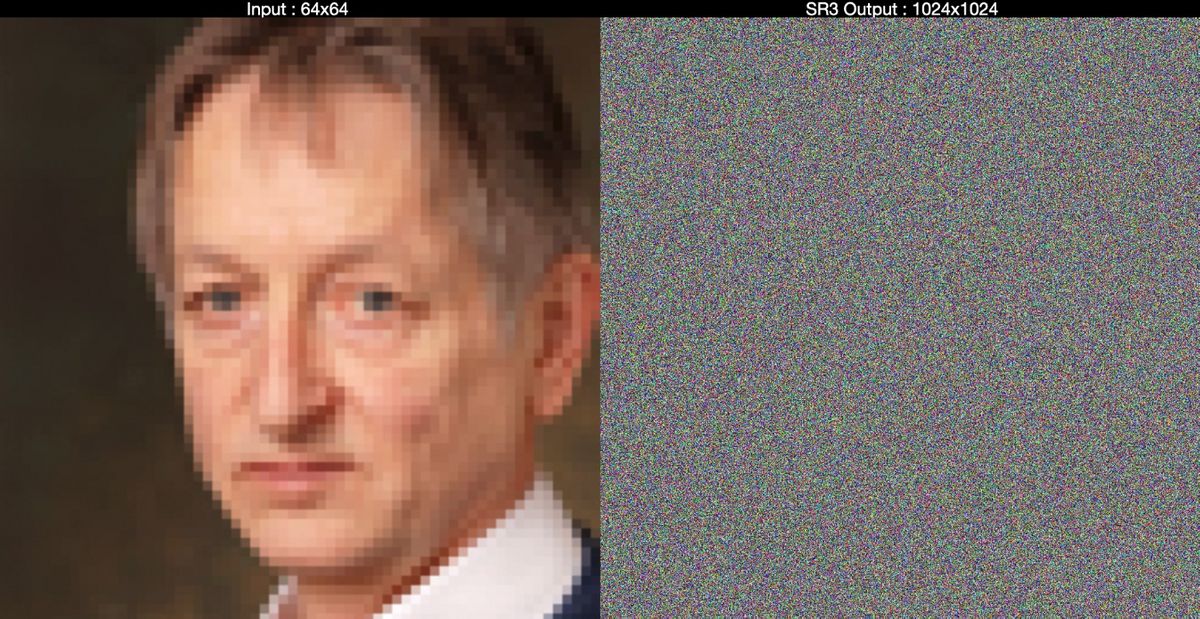
서서히 '순수한 노이즈 이미지'에서 노이즈를 제거해 가다보면...

최종적으로 원본 이미지보다 훨씬 세밀한 얼굴사진이 생성되었습니다.

여성의 사진에서도 동일하게 작동합니다.

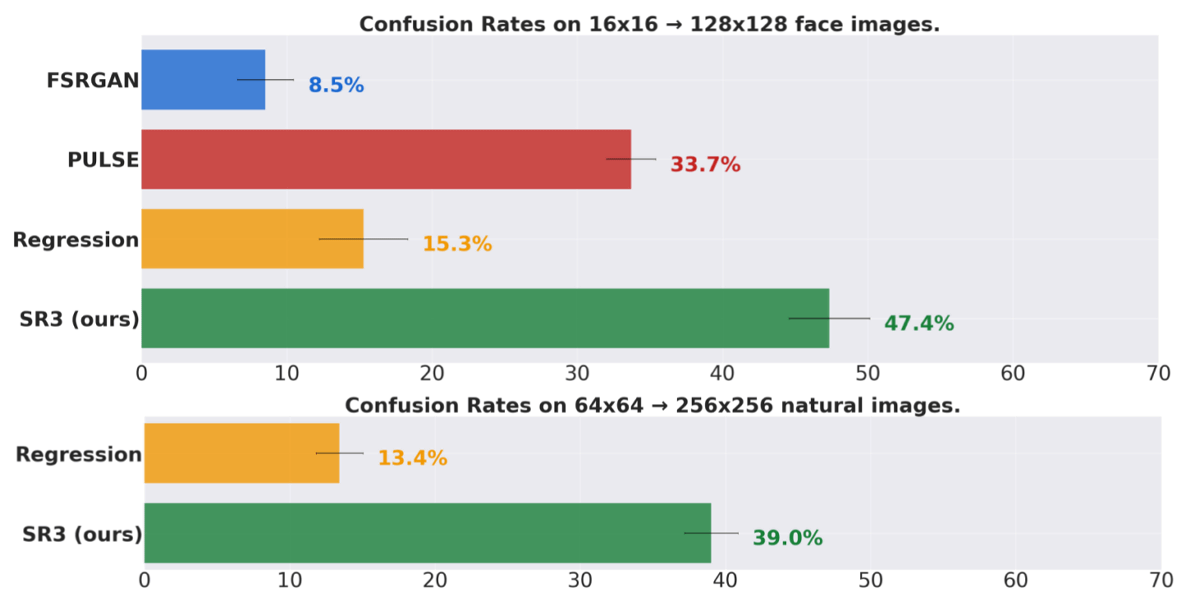
실제로 연구팀이 피실험자에게 '원본 이미지'와 '저해상도 이미지에서 다양한 방법으로 생성한 이미지'를 보여 어느 쪽이 원본 이미지인지 판별해달라고 요구한 결과가 아래와 같습니다. 피실험자의 오답율이 50%에 가까울수록 AI가 생성한 이미지와 원본 이미지의 어느 쪽이 진짜인지 판별이 되지 않게 되었다는 것입니다. SR3는 FSRGAN(Face Super-Resolution Generative Adversarial Network)과 PULSE, Regression(자기회귀생성모델) 수법과 비교하여 '16×16픽셀의 이미지를 128×128픽셀로 한 경우'(위)와 '64×64픽셀의 이미지를 256×256픽셀로 한 경우'(아래)에서도 오답율이 높아지고 있습니다. 특히 16×16픽셀의 이미지를 128×128픽셀로 한 경우의 오답율은 47.4%에 달해 피실험자는 AI모델이 생성한 이미지 대부분을 판별할 수 없었던 모양.
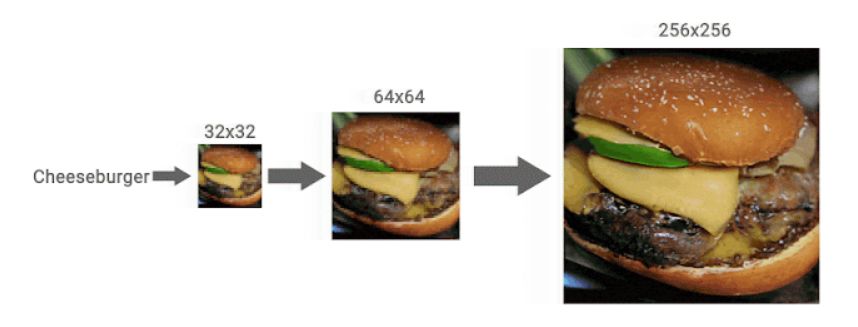
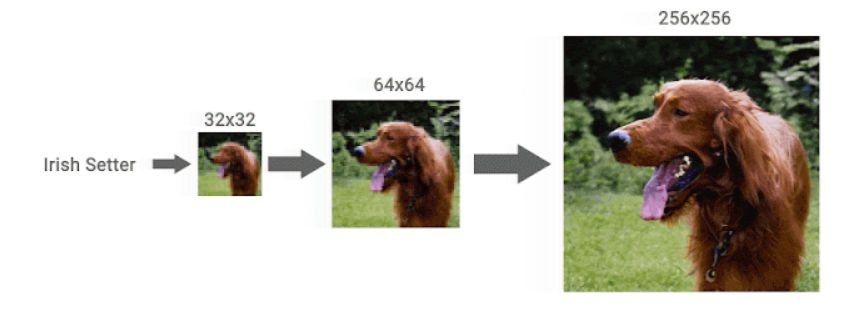
또 Google AI는 대규모 인식데이터 세트인 ImageNet에서 트레이닝한 클래스 조건부여(라벨링) 확산모델인 CDM도 발표했습니다. ImageNet에는 다양한 데이터세트가 포함되어 있기 때문에 생성하는 이미지가 원본 이미지와 동떨어진 것이 될 가능성이 있지만, CDM은 라벨정보와 함께 생성모델을 복수의 공간해상도로 서서히 업스케일링하여 고품질 이미지를 생성할 수 있다고 합니다.

'IT' 카테고리의 다른 글
| TikTok의 '동영상의 평균 재생시간'이 마침내 YouTube를 초과 (0) | 2021.09.07 |
|---|---|
| 하루 10만 건의 이메일 주소에서 찔끔찔끔 정보를 빼내 돈을 버는 해커의 수법 (0) | 2021.09.06 |
| 정부에 의한 '인터넷차단'이 급증하고 있다는 Google 싱크탱크의 보고서 (0) | 2021.09.04 |
| 곧 Twitter를 통해 비트코인의 송수신이 가능해질 예정 (0) | 2021.09.03 |
| Discord의 인기 음악봇 'Groovy'가 Google의 배제 통지에 서비스종료를 결정 (2) | 2021.08.27 |
| 누드사진을 얻기 위해 iCloud에서 62만 장 이상의 사진을 훔친 남성을 체포 (0) | 2021.08.26 |
| 6000억 원 상당의 암호화자산을 DeFi에서 훔친 해커가 전액을 반환하게 된 경위 (0) | 2021.08.25 |
| 세계적으로 HDD · SSD 품귀현상을 일으킨 암호화자산 'Chia' (0) | 2021.08.23 |



